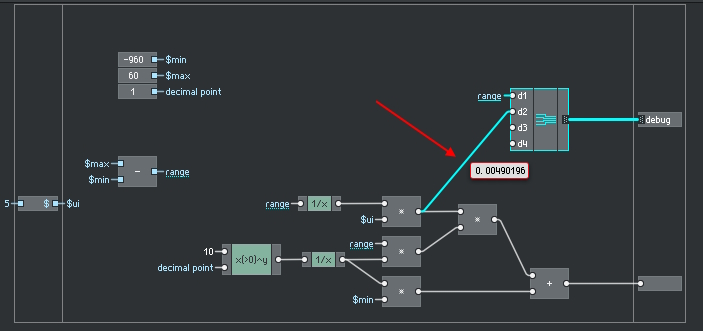
wanted to get some feedback about a test ens. My personal preference with building in core is to use as few "code" as possible. It enhances the readability a lot for me. But of course routing and latching helps a lot with reducing the number of computations. The question when to use routing can't be answered easily, that much I know. But a recent find confirmed my gut feeling in the following cases: (test ens attached below)
there are 100 voices, output is always zero because the array is empty. CPU consumers are the counter who has a router inside to reset to zero at max, the addition before the index, the read and the multiply. Everything happens at any audio clock.
CPU: 28% (i7 2700k from 2011)
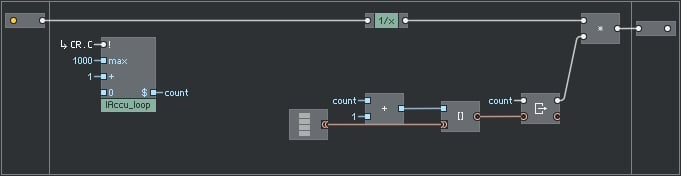
Now lets say we dont always need the multiplication, only 200 times out of 1000.

CPU: 21.6%
That's great! I added the 2nd router to show the following:

CPU: 21.4%
not better! The code looks as if there are less computations but there is no gain.
So here is what I believe: The computations done at the index and the compare module are only performed when there is an event present at the following read or router module. Could this be the case or is there a flaw?
Any flaws in my test ens? Any ideas to show these things in a better way? You own findings?
Thanks in advance